Pick and place has an odd status in robotics. It is often treated as the "hello world" of manipulation. It is useful and familiar, but no longer exciting. Reviewers often see it as largely solved. Research attention has shifted toward richer long-horizon tasks, language-conditioned behavior, and generalist robot policies.
And yet, pick and place is far from solved.
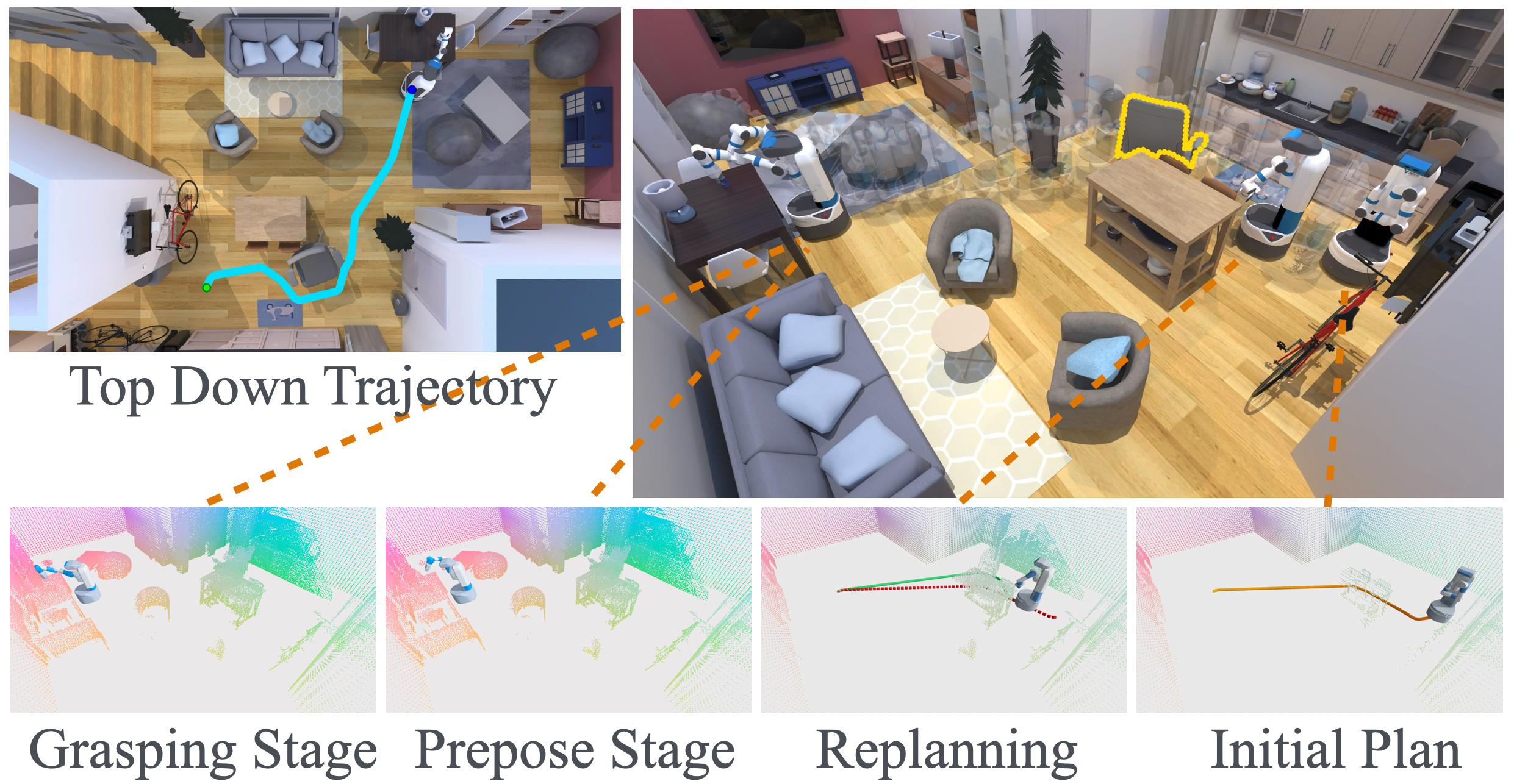
In our recent work, Visibility-Aware Mobile Grasping, we built a mobile grasping system that can grasp objects from arbitrary positions in real, dynamic environments. The system integrates active perception, whole-body motion planning, and adaptive subgoal generation to handle the full perceive-plan-grasp pipeline. We evaluated it across 400 simulation scenarios in 20 diverse indoor scenes and on a real Fetch robot at 5 indoor locations.
The bottleneck is grasping. Despite using a state-of-the-art grasp detection network, grasping failure is the single largest failure category in our system, in both static and dynamic environments.
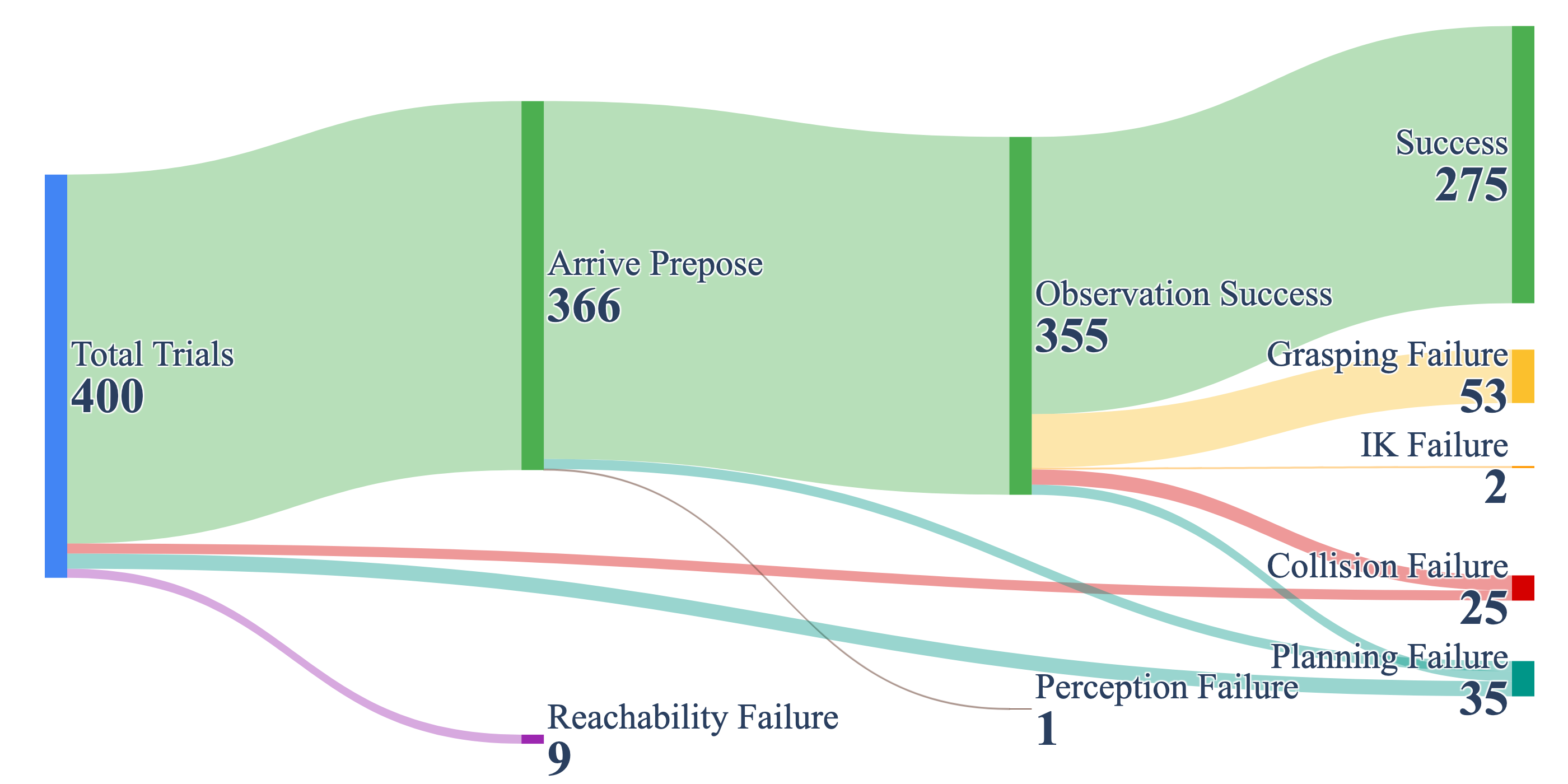
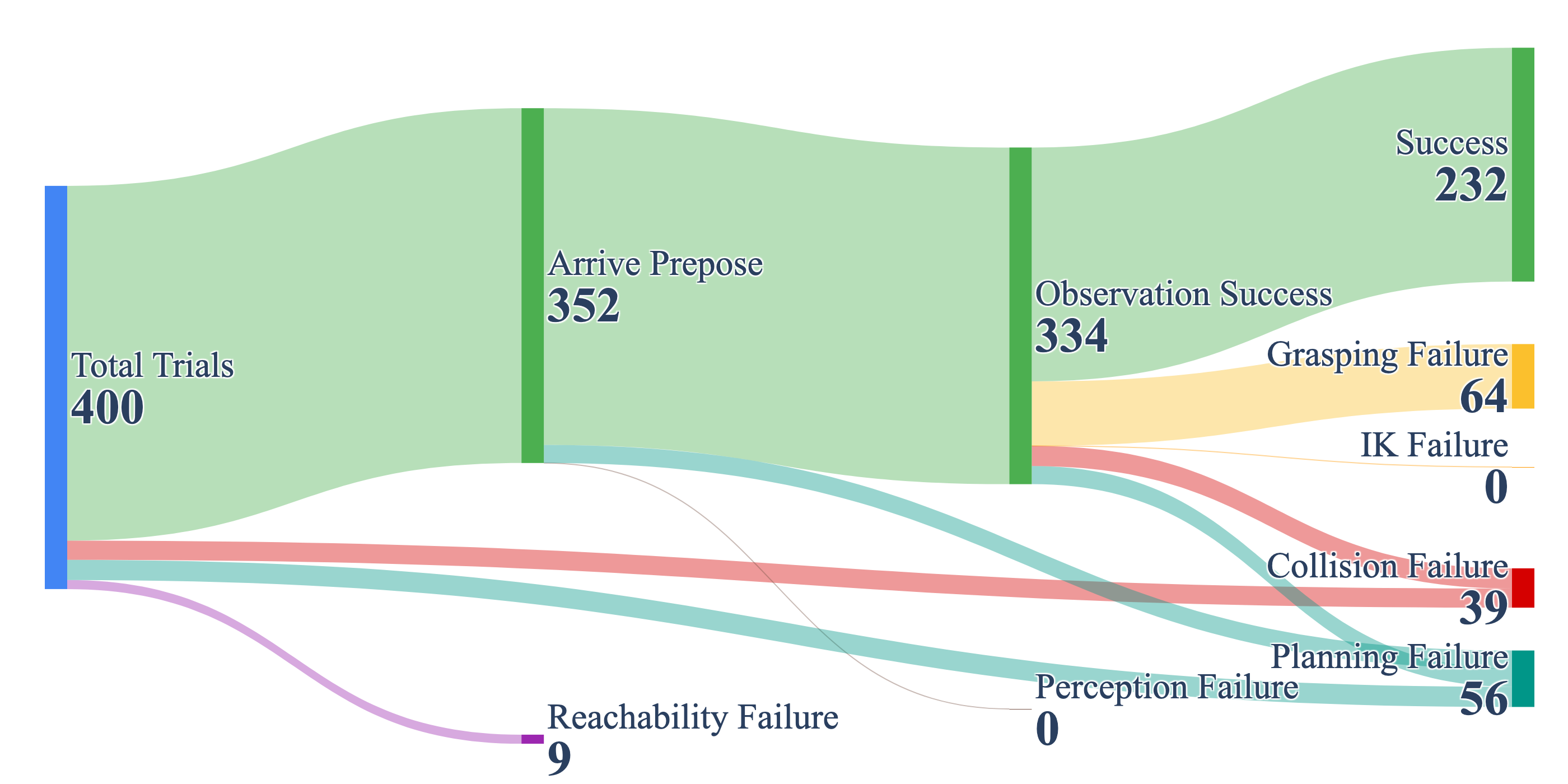
The flow diagrams make one thing clear. Grasping accounts for more failures than any other category. Out of 125 total failures across 400 static trials, 53 (42.4%) are grasping failures. When we dug into why, we found a consistent mismatch between standard off-the-shelf grasp detection and the demands of mobile grasping outside the tabletop setting.
This blog presents our failure analysis and what it reveals about the current state of grasping research.
The Grasping Gaps
We analyzed 46 grasp failures from our static benchmark in detail, manually labeling each into one of four categories. The breakdown suggests that some core assumptions behind tabletop grasping do not transfer cleanly to mobile grasping in cluttered environments.
| Failure Mode | Description | Count | % |
|---|---|---|---|
| Infeasible | All planning attempts fail or IK solution is in collision | 20 | 43.5% |
| Inaccurate | False positive grasp pose from the detection network | 14 | 30.4% |
| Instability | Object slips or drops after the gripper closes | 11 | 23.9% |
| Out-of-Distribution | Grasp network produces no valid candidates at all | 1 | 2.2% |
Each failure mode points to a place where standard grasping assumptions become fragile in our mobile setting.
1. Kinematic Feasibility
43.5% of grasp failures are not about detecting bad grasps. They are about detecting geometrically good grasps that the robot physically cannot execute.
The grasp detector scores candidates on geometric quality alone. In a tabletop setting, the robot is often pre-positioned at an ideal distance with a known workspace, so many detected grasps are reachable. When the robot arrives from an arbitrary starting configuration, the situation is different because it approaches from varied angles, often in tight spaces. A grasp that looks perfect in the point cloud may require an arm configuration that collides with a shelf, a wall, or the robot's own body. Of the 20 infeasible cases, 13 involved the gripper physically contacting the object but in a configuration where the full arm was in collision. The detector found a contact-viable grasp. The arm could not get there safely.
This gap has two facets. First, approach direction. Many grasp detection methods generate grasps without considering how the gripper arrives. Objects near walls fail because the approach angles are blocked. In those cases, a grasp on the object is not necessarily a "good grasp with a hard motion plan"; it may simply be invalid for the robot in that scene. Second, base-grasp coupling. Grasp detectors output 6-DoF end-effector poses without any notion of where the robot's base is or what whole-body configuration is needed to reach them. When the robot arrives from arbitrary positions, the workspace depends on the base position, and the base position depends on which grasps are available. In our setting, that coupling is hard to ignore.
2. Gripper-Object Mismatch
30.4% of grasp failures come from inaccurate detection. The network proposes a grasp that looks good but does not lead to a workable grasp on the real robot. The per-object breakdown reveals why.
| Object | Total | Infeasible | Inaccurate | Instability | OOD |
|---|---|---|---|---|---|
| Cups (various) | 14 | 2 | 8 | 3 | 1 |
| Lego Duplo | 8 | 4 | 3 | 1 | 0 |
| Toy Airplane | 3 | 2 | 0 | 1 | 0 |
| Mug | 3 | 1 | 1 | 1 | 0 |
| Clamps | 3 | 3 | 0 | 0 | 0 |
| Others (8 types) | 15 | 8 | 2 | 5 | 0 |
Cups dominate the failures, and their primary mode is inaccurate detection (8 out of 14). The issue is not just pose error. It is a mismatch between the detected grasp and the actual gripper kinematics. In the cup cases, the gripper is relatively large while the rounded cup edge is small. The detector proposes a grasp that looks reasonable geometrically, but during execution the second finger hits the opposite rim too early, so the grasp never closes around the cup body in a stable way. Lego Duplo blocks show a related issue. Small objects leave very little room for the gripper geometry and finger motion.
More broadly, this points to a limitation of current grasp detection itself. A grasp representation that transfers well across one gripper design does not automatically transfer to another. The detector may identify contact geometry that looks valid in the point cloud, while missing whether the finger width, closing path, and gripper shape are actually compatible with the object. In our setting, that gap shows up clearly on cups and other small household objects.
3. Grasp Stability
The remaining 23.9% of failures are instability. In these cases, the gripper closes on the object but cannot hold it securely. This category is smaller than infeasibility or inaccurate detection, but it still matters because it captures a different failure mode. The system reaches the object and makes contact, yet the grasp is not robust enough to survive lifting and transport.
Compared with infeasibility, instability is less tied to a single structural cause in our data. It appears across several object types, including mugs and small household items, suggesting that contact robustness, object geometry, and small execution errors all contribute. That makes it a natural target for better grasp ranking, tactile feedback, and post-contact adjustment, rather than geometry-only grasp detection alone.
Toward Grasping from Anywhere
Based on what we learned from building and deploying our system, here are a few directions that seem especially important for grasping beyond the tabletop.
Kinematically-Informed Grasp Scoring
The single highest-impact improvement would be grasp scoring that accounts for kinematic feasibility. Our data shows 43.5% of grasp failures come from infeasible grasps that score high on geometric quality. A clean way to formulate this is to score a grasp candidate \(g\) by feasibility, not geometry alone:
\[ y(g)=\mathbf{1}\left[\exists \pi \text{ such that } \pi \text{ reaches } g \text{ collision-free and executes the grasp}\right]. \]
Here \(\pi\) is a whole-body motion. With full scene information, a bi-level planner can label \(y(g)\) offline using motion planning, IK, and environment checks, then train a network to predict \(p(y=1 \mid o, g)\) from observation \(o\). That would let the grasp score absorb reachability, approach constraints, and scene geometry.
Model Gripper-Object Compatibility
A second direction is to make the model explicitly depend on the gripper embodiment \(r\):
\[ s = f(o, g, r), \]
where \(r\) includes finger width, jaw depth, closing path, and gripper shape. Our cup failures are exactly this problem. The pose looks plausible, but the second finger hits the opposite rim too early because the gripper is too large relative to the cup edge geometry. A grasp detector that is truly embodiment-aware should learn this mismatch directly.
Grasp Planning and Failure Recovery
Grasp detection alone likely has a ceiling. Some failures cannot be fixed by improving grasp pose prediction alone. Reliable grasping will require methods beyond grasp detection itself, including both grasp planning and failure recovery.
By grasp planning we mean deciding how to make the grasp possible in the first place. Sometimes the right action is not to grasp immediately, but to first change the situation: push the object to a more accessible pose, move it away from a wall, or relocate the robot so a safer approach becomes available. This is different from grasp detection. It is about planning a sequence of actions that creates a graspable state.
The second is failure recovery. Even with a good plan, execution can still fail, and the robot must decide what to do next. That decision can be written as a small action-selection problem:
\[ a^* = \arg\max_{a \in \mathcal{A}} \Pr(\text{success} \mid o, g, a), \]
where \(\mathcal{A}\) might include re-observe, shift base, change approach direction, switch grasp family, or retry under a different setup. Those labels can be generated from rollout or simulation instead of relying on ad hoc retries.
Evaluate Under Realistic Conditions
We need benchmarks that go beyond the tabletop. This means evaluating under varied viewpoints, with approach constraints, in cluttered environments, and with dynamic obstacles. It means measuring not just grasp success rate but the full pipeline, including perception quality, feasibility rate, recovery capability, and end-to-end time. A useful benchmark should expose both the partial observation used by the policy and the full state used for offline labeling. That would let us measure not only whether a grasp succeeded, but also why it failed: infeasible grasp, embodiment mismatch, poor recovery, or execution noise. That would make benchmarks much more diagnostic.
Citation
If you found this perspective useful, please cite:
@misc{grasping-gap-wild-blog,
author = {Hu Tianrun},
title = {The Grasping Gap in the Wild},
year = {2026},
publisher = {GitHub},
url = {https://h-tr.github.io/blog/posts/grasping-gap-in-the-wild.html}
}
@inproceedings{hu2025visibility,
title = {Visibility-Aware Mobile Grasping in Dynamic Environments},
author = {Hu, Tianrun and Xiao, Anxing and Hsu, David and Zhang, Hanbo},
booktitle = {arXiv preprint},
year = {2025}
}
Further Reading
- Hu, T., Xiao, A., Hsu, D., & Zhang, H. (2025). Visibility-Aware Mobile Grasping in Dynamic Environments. arXiv preprint. [Website]
- Fang, H. S., Wang, C., Fang, H., Gou, M., Liu, J., Yan, H., ... & Lu, C. (2023). AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains. IEEE Transactions on Robotics.
- Sundermeyer, M., Mousavian, A., Triebel, R., & Fox, D. (2021). Contact-GraspNet: Efficient 6-DoF Grasp Generation in Cluttered Scenes. In IEEE International Conference on Robotics and Automation (ICRA).
- Fang, H. S., Wang, C., Gou, M., & Lu, C. (2020). GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Newbury, R., Gu, M., Chumbley, L., Mousavian, A., Eppner, C., Leitner, J., ... & Asfour, T. (2023). Deep Learning Approaches to Grasp Synthesis: A Review. IEEE Transactions on Robotics.
- Morrison, D., Corke, P., & Leitner, J. (2020). Learning robust, real-time, reactive robotic grasping. The International Journal of Robotics Research, 39(2-3), 183-201.